NextApp is designed to use a distributed MVC pattern. The controller runs on the backend, and it can update any number of views on connected devices for the user.
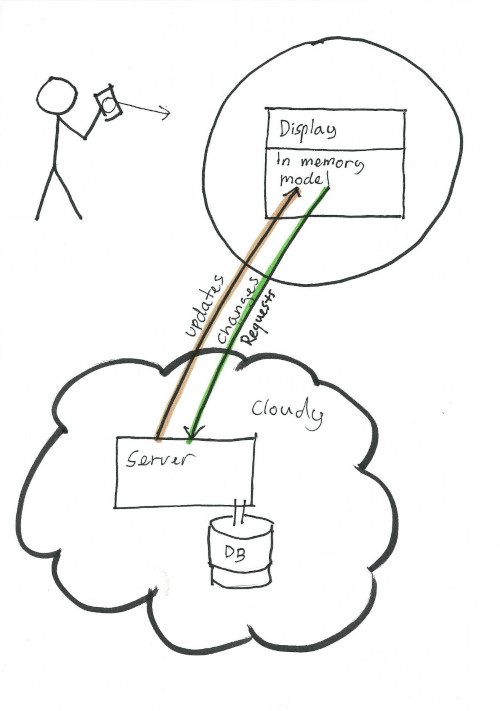
For example, I can run NextApp on my phone, laptop and PC and show the list of actions on all tree devices. If I change the name of an action on my PC, the PC will send a request to the backend (running in the "cloud") to change the name. The backend updates the name in its database, and then it send a notification about the change to all my connected devices. They all update the name of the action just as if the change had happened locally on each device.
Until now, the backend was also used as storage for all the information used by the app. When the app started, it would connect to the backend and ask for data as I switched between views. It basically worked as a web app, just significantly faster since compiled C++ code runs in rings around JavaScript. Recently, it became obvious to me that the design needed to be updated sooner than later to allow data to be locally cached. Getting everything from the server, all of the time, would just be too slow, not to mention expensive. So I spent a few hours over a weekend redesigning the architecture.
The original workflow
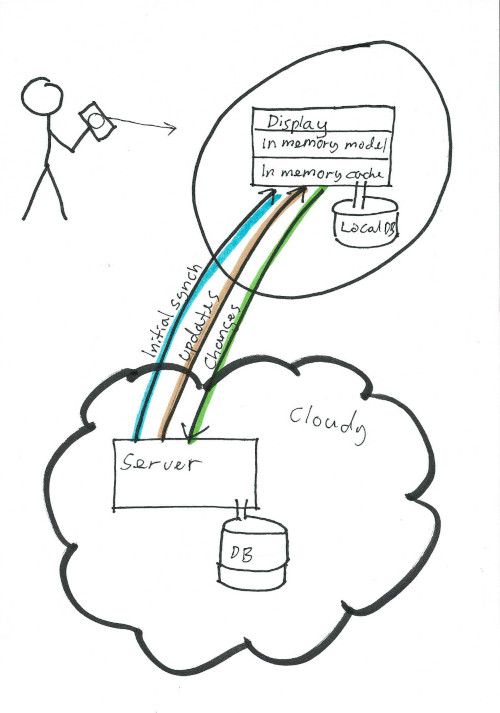
The new workflow
The workflows clarified by ChatGPT ;)
Replicating the data to work as much as possible locally was part of my initial idea for this app. But as I started to draft a MVP (Minimum Viable Product), I pushed this into the future. Data replication is complex. I am not aware of any off-the-shelf open source solution that can replicate structured data. My backend use MariaDB for storage. MariaDB can run "embedded" in an application. It is however not a good solution for a mobile app, if at all possible. Also, on the client I use QT, so it makes sense to me to use one of the databases supported naively in QT 6. SQLite is supported, and it is among the best tested and battle hardened databases available today. So that's what I chose for the client. As a side note - I use SQLite in my VikingGTD Android app. Over the years the database on my phone has grown to tens of thousands of items. Still, the app is as fast now as it was when the database was practically empty. A decade of very good experience with SQLite on mobile was also a factor.
The hardest problem to crack with data replication is how to deal with conflicts when two clients update the same data to different values. This is not a huge issue in a app like NextApp, as the user will typically use one device at the time. A situation where two devices comes to the server simultaneously with conflicting changes to the same data item (for example a calendar event) is unlikely. But if the app gains some popularity, it will eventually happen. There is also the possibility that if you work off-line with two devices, they both accumulate changes that will create conflicts. To prevent that mess for now, all changes must be sent to the server. If you want to change anything, the app must be on-line.
Even with relaxed requirements, which is what a central server that handles all updates atomically is, replication is not totally trivial. For example, how do the system know what data that needs to be sent to the clients? There are several ways to solve this problem. In my DNS server (which has a similar requirement), I store all updates in sequential order in a database table. The replicas will fetch from the first unseen update when they start replication. This is similar to replicating data via a stream like Kafka or Pulsar. I was tempted to use Pulsar with nextapp. However, in a GTD app there will typically be lots of changes that cancel each other out, like moving the deadline for a action from day to day or week to week for ages. When a device syncs up, it only need the current state. Another problem with "real" streaming is that it require a cluster of servers (or VM's) and use quite some resources. So it's expensive to host it in the cloud. For nextapp, I decided to just replicate all the relevant database tables when a device connect to the server. So I added an updated column in the table definition of type TIMESTAMP with milliseconds resolution, and a trigger that refresh that value whenever a row is updated. All the timestamps are from the same server, so there will not be errors caused by unsynchronized clocks. Then I added gRPC methods where the app can ask for all updates from a certain point in time (using the last timestamp received from the server for that table). For a new device with no cached data, that means that all the data for the user is sent before the app can be used. But normally the update will not send any data at all because the device already is up to date. When the app starts up, it subscribes to changes from the server. When a user works trough the day, all the connected devices will receive update notifications and keep their caches up to date, as well as showing the latest state in the UI.
Do you see the potential race condition? What if a user updates something when another device is doing its on-connect-sync, or a full sync? If the device subscribes to updates, it may receive a row that is newer than one that will arrive later in the sync. The new row may even reference some other data that is still not received, breaking a database constraint! If the device subscribes to update after the sync, it may receive the old item and never see the updated row. The current implementation subscribes to updates before the sync, but any updates received during the sync is just put in a queue. After the sync is completed, the updates are processed. Only updates that are more recent than the stored data is applied.
Internally the app has several caches. For example a cache for actions, and a cache for calendar events. When some data model (the component that provide data to a list or tree in the UI) need a window of data, for example today's calendar events, it asks the calendar cache for that data. The cache keeps all items currently used by any model in memory. One item will only be cached once in memory, even if several models use it. This helps reduce the memory footprint for the application. When the app receives an update notification from the server, it emits a signal, so that all the caches can see if it is relevant for them. If for example a calendar event is moved from one day to the next, the calendar cache will reorder its events, and then notify the UI components for the two relevant days that their data has changed.
When a cache is asked for data, it queries the local SQLite database. It will then update its cache so that everything a model asked for is in memory. Then it returns a list of pointers to the relevant data to the model. A model will never ask for lots of data, for example all the actions in the database, in one request. It use QT's lazy loading pattern, so that if the user want to scroll over all the actions in the database, it will only fetch some actions at the time, and then as the user scroll down, it will ask for more.
Another interesting problem when all the date is replicated on startup, is how to handle deleted data. I worked for a company some years ago that made a globally distributed active-active database. If our cluster in a regional data-center failed to replicate changes from other regions, the idea was to simply send all the new data from the nearest operational data-center. There was lots of data, so taking a region off-line to restore a backup and then get replication to work was slow and not very reliable. The database was supposed to be "eventually consistent", but in the 3 1/2 years I worked there, there was no working solution to delete items in a data-center that synchronized changes with another data-center. In NextApp, I have solved this by not actually not deleting data on the server (unless a user is deleted). In stead, Objects that the user deletes is reset (all information except the id and the fact that it is deleted is removed). When the user gets the stream of updated items at start-up, it also get the deleted items, which it can then delete from the local database.
There is another interesting problem with deletions. In a database, it's common that one object references another object. If the object being referenced is deleted, all objects referencing it is also deleted. This happens recursively. For example; if I delete a user in the system, the database will delete all its data in all the database tables. This is because all data objects belonging to a user references the user object directly or indirectly. But what about less dramatic deletions. For example, an action can be referenced by work-sessions, which tracks when I worked on that action. This functionality allows me to see exactly how much time I spent on an action, and when I worked on it. It also allows me to see how many hours I worked last week, and on which actions. There are models in the app caching both actions and work-sessions. If I delete an action, the server will delete all the work-items for that action as well (mark them as deleted), and send notifications to all the connected devices about these changes to the caches and UI can be updated. That's fine for changes with just a few cascading changes. There is one object, a tree-node, that can have tens of thousands of objects referencing it. A tree-node is a list in GTD terminology. It's where the actions are located. If the node is deleted, all the actions in that node, and all the work-sessions for all those actions must also be deleted. I treat this like a special case. On the server I actually delete the node, to trigger a database driven cascaded deletion of all the referencing objects. Then I create a new empty object with the same id and the deleted state. When the app is informed about a deleted node, it must delete all the referencing objects in the local cache, and then refresh all the data models that may be affected, so that the information presented to the user is correct.
This was a big change, affecting almost everything in the client app. But it did make the app faster to start up and work with, and the server is mostly just replying to ping messages now. Ping messages is a common way to detect if an app still is connected to its server.