Async model
My understanding is that the "Async" model was the original approach to support async processing of gRPC calls. This applies for both server and client side.
The async model is something entirely different from some other "async" patterns you may be familiar with; for example boost.asio async operations, C++ 20 co-routines or even Node.js's futures.
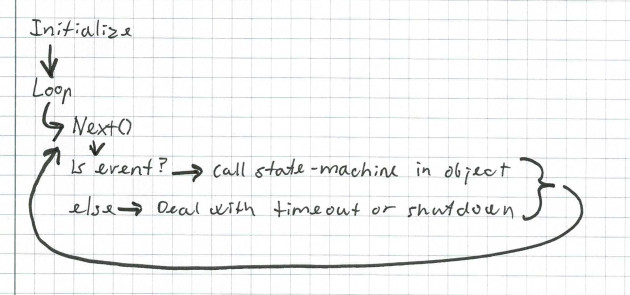
In async gRCP, you have a Queue. The queue has a Next() method, and when you are ready to handle the result an operation - any operation - this is the method you call. When Next() returns, it means that some async operation has finished (or failed).
The work-flow is: You initiate one or more async operations. Each operation is directly or indirectly handed a pointer to your Queue. Then at some later time, you call the queue's Next() method to wait for any of the operations to finish. When that happens, you process the operation, for example an incoming rpc request to a server. If appropriate, you initiate another async operation, and then your event-loop eventually gets back to calling Next().
In other words, this model require us to implement an event-loop and to provide a thread to run this loop.
When you initialize an async operation, you call a method on an interface that is implemented by the rpcgen code-generator for your specific use-case. Your use-case is described in your .proto file. The initialization tells gRPC what operation you are targeting, and what "Queue" you want to use. The details depends on the direction (server or client), and wether the operation involves streams.
When you call the queue's Next() method it will block indefinitely if no async operation completes. Alternatively, you may use AsyncNext() which allow a deadline argument about when to time out. When Next() returns, you get information about three states: The status of the call to Next(), a boolean status for the operation in question, and a void * pointer - that gRPC calls a tag. Based on these three states, and what you know of the previous circumstances for the object identified by the tag, you must decide how to deal with the event. As you can see, this is not just an event-loop, it's basically a looping state-machine. (Or worse, you can think of it as a good handful of raw co-routines without language or library support where you get to handle all the dirty details yourself).
Some of the examples I have seen on "the internet" tries to deal with everything in this event-loop itself. I would advice against that. Since we typically want to process multiple rpc methods and potentially a large number of simultaneous "sessions" or on-going requests, I find it simpler to implement the async interface as an simple inner loop, and each individual RPC operation as a outer state-machine.
Now, lets take a step back and look at the queue and the three states. First, the Queue has some serious limitations. It can handle a large number of items, but it can only queue one item with a specific tag. The tag is the value of void *. The queue takes no interest in your use-case, what the tag represents, or what gRPC methods you define. It's quite primitive. And, remember - it allows you to add just one request for any operation identified by a tag. You can use a pointer to an address of an object, or you can just use a unique number like const auto tag = reinterpret_cast<void *>(1);.
When you start an asynchronous operation, you supply a tag. After the operation is complete, you will eventually get the tag returned by Queue::Next() in your event-loop. The first event to happen depends on the operation and wether you are on the client-side or the server-side. For example, on the server-side, you may want to receive a request. So you add an operation by calling a class generated by rpcgen to handle a specific RPC call. When a client has sent a request, you will see the first event. If the request's argument is a normal prototype message, and not a stream, you can immediately look at the request and formulate a reply. Then your next event on that object will be that the reply was sent, or that it failed. If the request is a stream of messages, then your next operation will be to read the first message, and the next event on that object will be that the first message was sent or an error.
The complexity of your state machines increase from the simple request/reply work-flow with "normal" messages to request-stream / reply-stream flows.
For example, my DNS-server will handle replication from some column-families in a RocksDB database by having the followers connect via gRPC to the primary server. All the transactions on the primary server is then relayed to them in a bidirectional stream. The follower streams messages back to the primary - just not immediately. Every 200 ms, it will send it's last committed transaction id, if that has changed. That means that when a follower connects to the primary, it gets a flood of transactions until it has caught up. After that, it will receive new transactions as they are committed on the primary. The primary on the other hand, will wait for all it's up-to-date followers to have confirmed a transaction, before it replies to it's initiating client that the change is complete. So the architecture is a totally asynchronous bidirectional stream. After an initial message from the follower about what transaction ID is has last committed (which could be 0), there is just a weak correlation between the two streams. Each side push messages as they become available or a timer expires.
An Example
Let's start with the simplest possible use-case; a traditional RPC (Remote Procedure Call) request with a request argument and a single reply. The only complexity we need to handle is multiple, simultaneous incoming requests. That means that it makes sense to create an object to represent an individual request. We can use a pointer to an instance of that object as the tag.
The protofile:
rpc GetFeature(Point) returns (Feature) } int32 latitude = 1; int32 longitude = 2; string name = 1; Point location = 2;Server, trivial unary request/response messages.
I have chosen to use a C++ class for the implementation of the async server.
The initialization is trivial:
Example output:
async-server2023-07-17 15:16:56.699 EEST INFO 17607 async-server starting up.2023-07-17 15:16:56.709 EEST INFO 17608 SimpleReqRespSvc listening on 127.0.0.1:10123The event-loop is also simple. It waits for the next event to become available on the queue and deals with timeout and shutdown. If there is a tag, we cast the tag to a pointer to an instance of our request class and call it's proceed() method (we'll get to that soon). That will run the objects state-machine to its next state.
while bool ok = true; void *tag = ; // FIXME: This is crazy. Figure out how to use stable clock! const auto deadline = + ; // Get any IO operation that is ready. const auto status = cq_->; // So, here we deal with the first of the three states: The status from Next(). switch case grpc::CompletionQueue::NextStatus::TIMEOUT: LOG_DEBUG << "AsyncNext() timed out."; continue; case grpc::CompletionQueue::NextStatus::GOT_EVENT: LOG_DEBUG << "AsyncNext() returned an event. The status is " << ; // Use a scope to allow a new variable inside a case statement. auto request = static_cast<OneRequest *>; // Now, let the OneRequest state-machine deal with the event. // We could have done it here, but that code would smell really nasty. request->; } break; case grpc::CompletionQueue::NextStatus::SHUTDOWN: LOG_INFO << "SHUTDOWN. Tearing down the gRPC connection(s) "; return; } // switch } // loopThere are a couple of things I don't like with AsyncNext(). It use void * to totally erase the type of tag. This is an anti-pattern in C++, as it prevents the compiler and common tools to catch type-related errors. My guess is that they have done it this way to maximize performance and flexibility. However, I think they should have provided a type-safe alternative.
Next*() takes pointers in stead of object references. This is often a pattern in C++ when an argument is optional. However, that's definitely not what's going on there, at least not for ok. Also, The ok argument have multiple meanings, depending on the context. This makes it harder use. A status enum would probably have been a better option. In the client, there is a status class used in addition to ok, which makes that interface even harder to comprehend and implement correctly. Then there is the use of a deadline that uses absolute time-points in the future, allowing std::chrono::system_clock::time_point but not std::chrono::stable_clock::time_point. Crazy! A better approach would have been to just accept a std::chrono::duration type, for example: std::chrono::milliseconds(123) or just an integer representing milliseconds. Using the system-clock will not provide accurate timeouts because of time-skew and time-corrections done by the operating system.
But we developers have learned to work with what we have. That's a huge part of the cool with software engineering ;)
I have created a OneRequest class for the simple state-machine for our RPC handler.
The first thing it does when it's created is to call service_.RequestGetFeature() where service_ is an instance of async service, generated by protoc from our .proto file.
This statement gives gRPC one instance of something that can deal with a GetFeature request. It will use it only once. Therefore, one of the first things we do in our state-machine when it is called, is to create a new instance so that gRPC have somewhere else to dispatch the next call to this rpc method.
In the case of a unary rpc call (a method with a single protobuf messages as request, and a single protobuf as reply), the state-machine is quite simple.
- We initiated the operation with RequestGetFeature in the constructor.
- When a client is doing a rpc call, we get called in state CREATED.
- We initiate the reply operation and return control to the event-loop.
- When the reply is sent, we get called again with in state REPLIED.
Note that the state is our own invention, and that gRPC knows nothing about it.
// State-machine to deal with a single request // This works almost like a co-routine, where we work our way down for each // time we are called. The State_ could just as well have been an integer/counter; void void That's pretty much the complete server side implementation for this one RPC call. The complete source code.