
Have you ever implemented something like a web service with some kind of authentication, for example an API key or a JWT token? How did you deal with it in the server? One pattern I have observed is: The server has a cache of tokens it knows are OK, and when a request comes in, and the authentication token is in the cache, the request is served immediately with whatever privileges the token grants. If the token is unknown, the request is put on hold, and the server either take a closer look, for example by looking up the relevant information in a local data storage, or it might ask some other specialized service about the token and it's permissions. Once the mystery is solved, the token goes in the cache, and the request is resumed and processed using the appropriate permissions.
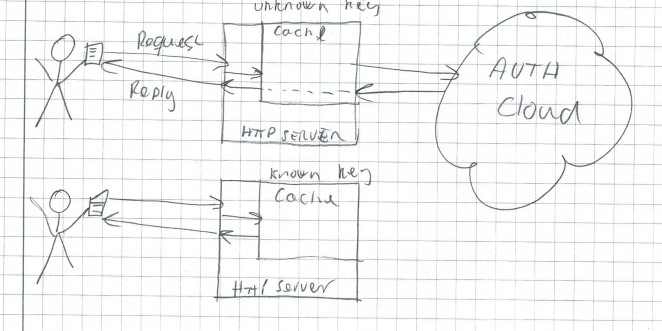
Well and good. Except for two things. How do you put the request on hold while the mystery is being solved? This is particularly relevant for mysteries that must be solved by doing requests to other services. Do you lock the thread handling the request on a mutex or on a future? That can be quite wasteful, unless you are working on old enginering principles with one process or one thread exclusively processng one request. If you use modern C++, you probably use one thread per core, and asynchronous methods like asio stackfull coroutines or C++20 coroutines. If your cache has to block the thread to do a lookup, it will break the one thread per core principle and force you to have a generous pool of worker-threads to to deal with the showstoppers.
And how do you deal with the situation where more than 1 request for the same token arrives before the token gets inserted into the cache? One common approach is to let each request trigger the whole work-flow, and basically spam the data-storage or back-end with the same request again and again, until one of the requests are completed and the token makes it to the cache.
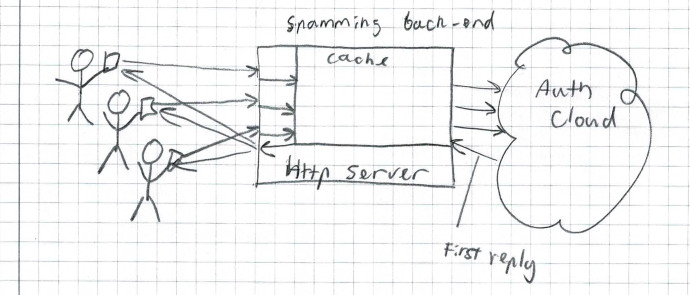 (Three users using the same key simultaneously)
(Three users using the same key simultaneously)
A better implementation, in my view, will be something that is asynchronous (so that the thread can go on with other tasks while the mystery is being solved) and one that only solve one particular mystery once.
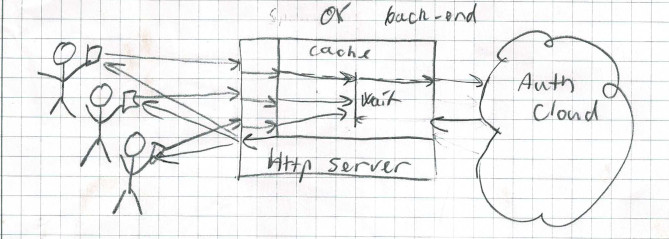 (Three users using the same key simultaneously)
(Three users using the same key simultaneously)
I have implemented these challenges in the past in commercial code. Now I needed it again, this time for several open source projects I am working on.
So I created a generic C++ template class to deal with this once and for all. My projects all use asio, and they use asynchronous code. Some sections use stackfull coroutines (to handle complexity), other stackless coroutines or callbacks (for better performance). The cache must therefore offer asio composed completion methods. They will work with any continuation supported by asio, including C++ 20 coroutines.
The cache acts like a trivial key/value store. During instantiation, it gets a functor that know how to fetch the data if is not in the cache.
The use could be, for example in an asio C++ 20 coroutine:
// Create an asio/C++20 co-routine ;... Or using a traditional callback:
cache.;This will nicely integrate with my applications which typically use exactly the same pattern to handle network communication.
If you are unfamiliar with C++ and coroutines, the code above probably looks like traditional, sequential code. In reality, the cache.get() call may put the function on hold, frees the current thread up to do some other stuff, and then, when the value is ready, resumes its operation, potentially in another thread, and continue exactly where it left off. This pattern allows us to write massively performant applications where a single thread, or one thread per CPU-core can handle tens of thousands of simultaneous requests. And we can do that without using callbacks which allows a similar pattern, but with a terrible cost when it comes to the readability of the code.
In the examples above, if the key is available in the cache, the function returns almost immediately with a copy of the value. If this is the first time the key is requested, the cache will put the request in a queue of requests waiting for this key, and then free the thread for other work. If more requests are seen for the same key, they are added to the list of requests waiting for the value. Once the value is available, it is added to the cache, and all the requests waiting for the value is scheduled to resume their work. That will happen as soon as appropriate threads becomes available for them.
This kind of logic is not new. But traditionally a smart asynchronous cache like this would be hard to implement, it would be written specifically for a critical use-case, and it would be hard to test. With C++ 20 and boost 1.81, it was relatively simple to make a totally generic, testable implementation.
In some use-cases, the values may need to change over time. For example, if the cache is for API keys, we need a way to deal with modifications in a users access-level, or the removal of a user or the revocation of a key. In my cache, I have added an invalidate(key) method for this. A server may have a side-channel, like an event-stream with API keys that are changed or deleted. (I have used Apache Pulsar in the past to provide such streams). In the simplest, case invalidate(key) just removes the key from the cache, and the next time someone asks for it, it is fetched like any unknown value. But what if I invalidate a key where we are currently fetching the value, with one or more callers waiting for the result? The simple option would be to return an error to the queued requests, and hope that the requests will try re-tried. My actual implementation looks at the state of the key. If the key contains a value, the key is removed. If the key contains one or more previous requests, waiting for the key, the key is just flagged as invalidated. When the fetch operation for the actual value completes, - in stead of handing the value to the waiting callers, the value is ignored, the invalidated flag reset, and the fetch operation for the value re-tried. - After all, we have no way of knowing if the received value is the old (before the invalidate) or the new (valid) value.
The cache is implemented as a header-only library, and can trivially be included in projects using cmake includes. It's available on github under the Boost (BSL-1.0 license) - the same license as the Boost libraries. I use std::string as both key and value in the examples here, but the implementation takes the object types a template arguments, so both key and value can be pretty much anything - as long as they are copyable and movable. For complex value-objects, it makes sense to use std::shared_ptr<Type> as the value-type, so only a reference is handed out by the cache.
I've used Debian Bookworm and Kubuntu 23.04 to implement and test the code.