NextApp is a GTD/productivity application for desktop and mobile.
On May 31st, I was finally able to release the first public Beta.
Building
I built everything, except the Android app, on GitHub. It took considerable effort (weeks of work) to get each platform compiled and ready with static Qt. For Linux, that effort turned out to be mostly wasted, as vcpkg can now build a static Qt 6.8 app for Linux with significantly less hassle than building Qt statically myself. By the time of the release, Qt 6.8 was also supported by standard Flatpak base platforms. That's probably the direction I’ll go in the future, even if the initial user download is quite larger than my current statically linked app.
After working through the Windows build (including a nice installer) and the macOS .dmg, I was pretty worn out. Just getting the macOS app properly signed, using a script that runs as a GitHub Actions workflow, integrated with CMake, took days. I then spent about another week trying to build Qt statically (or not) on Ubuntu and to cross-compile the Android version for ARM64. I almost got it working with vcpkg, but unfortunately, vcpkg also cross-compiled the protobuf tools. These are needed on the host machine by CMake to generate source code for protobuf and gRPC. Eventually, I decided to stop being an idiot and just build the Android version in Qt Creator for now.
I also ran into an issue with the Windows build on GitHub: the build takes about six hours, and GitHub Actions terminates any job that exceeds that limit. So I’ll likely drop GitHub Actions for anything beyond backend containers.
I fixed almost all the known bugs. I don’t want to ship a buggy product. But I also can’t afford to be a 100% perfectionist if I ever want to actually ship anything.
Nextapp's homepage
Then there was the homepage. Some years ago, I decided to create a homepage for my Bulgarian company, "The Last Viking LTD." When I started the company, it was just to open a café in a little village I cared about, to make it nicer. At the time, I worked as a senior C++ developer for a start-up in the capital, Sofia.
After a few years, I decided to return to freelancing. Since I already owned a company, even one with a decent name, I simply created a new branch for my freelance work. Another few years later, I decided I wanted a web presence.
In the far past, I had my own quite nice content management system, using PHP with a module written in C++ to speed things up and provide decent security. However, maintaining such a system is a pain. So I looked for something new. I discarded WordPress because of its horrible security track record. I tested a few alternatives. They all turned out to be anything but easy to bootstrap. One of my requirements was that the site must work equally well on mobile and desktop. I couldn’t find anything that was both 1) easy to bootstrap and 2) mobile - and desktop - friendly.
So, as I often do, I wrote my own: stbl. This time, I decided to go for a static website generator. That makes hosting simpler, scales well, and has zero supply-chain vulnerabilities (an enormous problem in today’s web space). Since my new site, lastviking.eu, was primarily for blogging, stbl became a static blog generator with adaptive banner images (scaled down to various sizes during generation) to fit any device perfectly.
With the release of NextApp, I needed something else: a landing page with multiple banners, static pages (like documentation), and a blog. I made some modifications to stbl over the last few months. Of course, when I tried to generate the actual website for the app on the 31st, stbl found ways to fail. Fortunately, it wasn’t hard to fix.
One of the features on the app’s webpage, next-app.org, is a feedback form at the end of the front page. I had "Make a backend for feedback" as a priority action in NextApp for months. My original plan was to write something in C++ using yahat-cpp as a web server, but I ran out of time. Instead, I made a very simple Rust application where feedback is written to a SQLite database. I was amazed by how simple it was to create a multi-step Docker container to build and deploy a Rust server (thank you, ChatGPT!).
Metrics
A few years ago, I worked with a California-based startup developing a globally distributed database. After some hectic months, they launched a free trial, only to realize they were completely blind. They had no centralized logging or meaningful metrics. That changed dramatically over the next few quarters. They started adding metrics everywhere, for everything. So many metrics, in fact, that a cluster of hefty AWS instances ran at, if I recall correctly, 20% utilization even with no user activity. It was insane.
So when planning NextApp’s beta release, I knew I needed metrics. I also knew they could get expensive. Choosing what to measure matters. A while back, I added OpenMetrics support to my yahat-cpp embedded web server library. For the backend, I included just a handful of key metrics:
- Number of signed-up users
- Number of devices
- Number of active user sessions
- gRPC request latency
- And a few others...
Far fewer than any other applications I’ve seen. The rationale was simple: only track what’s necessary to detect problems and understand system usage.
For the client application, I decided against any telemetry at all. Not because all telemetry is intrusive or evil, but because too many companies abuse it to collect intrusive data. Personally, I feel uneasy every time an app even mentions telemetry. I don’t want NextApp’s users to feel uncomfortable about anything.
Logging and Diagnostics
Another critical aspect was logging. When I worked for that globally distributed database startup, I happened to be one of their most senior developers. Consequently, most critical production issues landed on my desk. For example, production servers crashing. Productions servers running like black boxes without any meaningful logging or metrics.
To address this, I wrote a new deployment script that integrated logbt into the database server’s container image. While I was at it, I also patched heaptrack to work with Docker/Kubernetes and added it as a build option. With these two tools, we identified the root causes of several crashes. Around the same time, I discovered Loki, a log server that was in beta back then.
Initially I used logbt for NextApp’s backend. That was, until I learned about Boost.Stacktrace. The main drawback of logbt is that generating backtraces is slow, delaying container restarts. With Boost.Stacktrace (without symbol resolution), the container exits in just milliseconds. Since I generate a symbol map during the build process, I can resolve symbols post-mortem if the server crashes.
For backend logging, I chose Loki. It’s not perfect, but it’s easy to use and integrates well with Grafana, which I use for the dashboards monitoring NextApp and its VMs.
Shortly before the beta release, I added JSON output as an option in logfault (my logging library). This produces log output like this:
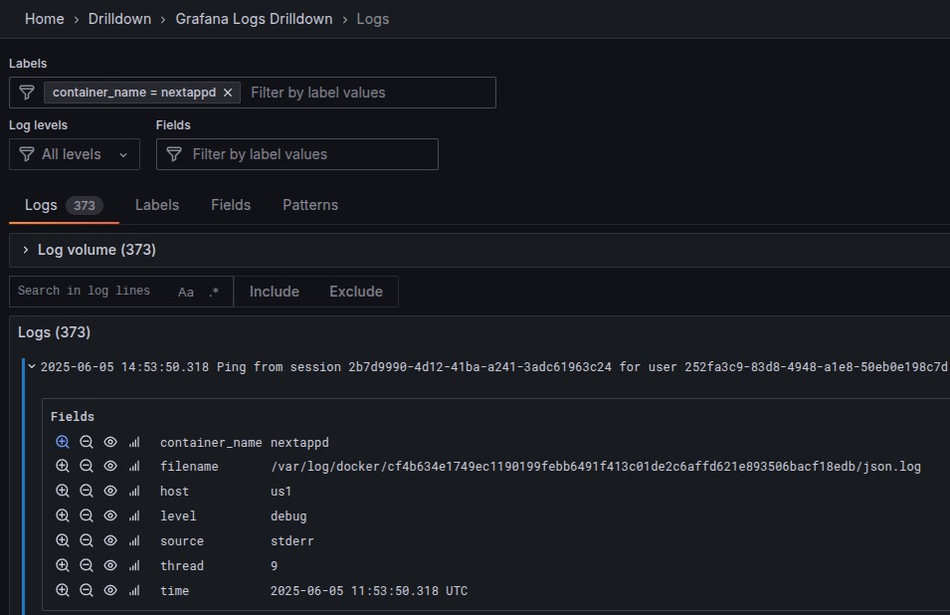
Here, labels from the container deployment and the log-event’s JSON payload are merged into the Fields list. I also have full control over the displayed log message, because it is one of the json strings in the log-event.
When I was at it, I also added a compile-time option to set a minimum log level, and disabled trace messages for production builds. That allows me to have a zillion log statements at trace level in the servers, and let the compiler optimize them away for the release builds. Even if each log statement is cheap (each statement is evaluated against the log-level before the actual log statement is even processed), a zillion integer comparisons still takes some time. And, one evening I was too tired to do anything useful, I added a variadic template interface to the logger, that allows it to add context from C++ objects. It works a little bit like the templates we use to expand std::format to handle our own data types. In my servers now, I use it to add json data about the tenant and user for each gRPC request.
--
try RequestCtx ; // Note the rctx argument to the log macro << "Request [" << name << "] " << req->-> << ": " << owner_.;The function that expands rctx to something the logger can use:
// nsAs long as the declaration for toLog is visible when logfault.h is included, any object can be passed to individual log statements. The JSON format is optional. I use it primarily because JSON formatted logs integrate well with Loki.
Btw, I use the same log library in the client. The app has a QT model with a circular buffer for log messages you can watch from the app, notifications for errors and warnings, optional logging to file, and logging directly to the Android system for the Android version. All using the same log statements in the app. And offering the same compile time switch to optimize away trace log statements.
Securing Metrics Endpoints
Originally, I planned to use IP whitelisting to secure the metrics endpoints. However, thinking about it over a coffee, I realized I did not want the payloads to go unencrypted over the public internet. The metric endpoints from my servers supports HTTPS. Cadvisor on the other hand does not. I use that to get information about the containers in the VM's. Eventually, I decided to make things simple for myself and use WireGuard to keep all the production machines connected to a VPN. I created an ansible playbook to deploy WireGuard, collect all it's pubkeys and create the local configuration files on each VM to keep them connected. It's the first time I use WireGuard. In the past OpenVpn was my goto solution for VPN. WireGuard turned out to be much simpler to configure.
With a VPN, the ports used for metrics and other internal traffic can be blocked from Internet with the VM's firewalls, or the cloud providers firewalls. To tighten the security a little further, I make sure that the Linux kernels has IP forwarding disabled. That means that the VM's can not be used as exit nodes from the VPN, and that only services that binds to the VPN's local IP, or all IP's, are available to other nodes in the VPN.
devops automation with Ansible
For the deployment of the production VMs for the backend, I created simple Ansible "roles" to handle common tasks, like setting the hostname and forcing sshd (OpenSSH) to allow authentication only through certificates. I don’t really understand the reasoning behind having multiple individual settings in its configuration file to disable password authentication. From my perspective, that is not best practice for keeping a core component on Internet - used on millions of production servers - secure. (It reminds me of how badly AWS screwed up when they designed S3 security, where “authenticated user” means any authenticated AWS user, not a user authenticated within the organization that owns the bucket. God knows how many "data breaches" can be traced back to this.)
We, as software developers and architects, need to take IT security seriously. Anything that can pose a risk should be unavailable or disabled by default.
Anyway, I continued by creating playbooks for deploying and upgrading my services, setting up metrics for the VMs, logging (I used Loki’s Docker log plugin), and copying TLS certificates, EULA, and welcome text for new signups from my workstation. All secrets are safely stored in Ansible Vaults.
It took me almost two full days to prepare the deployment. It would have been much faster and simpler to just do it manually. But it’s easy to forget a small detail when deploying manually. Doing it properly is a pain, but it pays off by reducing the chances that things blow up.
Although, Ansible playbooks must be tested as thoroughly as any other production-grade code. A simple bug in a config file can easily kill a service like Docker and require manual intervention (or a new playbook) to clean it up. Guess how I happen to know that. ;)
Conclusion
It was nice to finally release NextApp. There are still a few man-years of work left before it’s anywhere near where I want it to be. But that will always be the case with complex software I really care about. It’s quite useful in its current state. I hope to build a small community of active users, so the direction going forward makes NextApp genuinely useful for a larger number of people.